Quem tem fome tem pressa, muita pressa.
Que o uso de dados cresce exponencialmente a gente já sabe e o chavão “dados são o novo petróleo” deixa um apelo para que as pessoas cada vez mais se insiram nesse contexto. Não é exagero dizer que estar à margem da cultura de dados já denota uma condição social inferior, assim como a perda de oportunidades: de conhecimento e de emprego, entre outros. O ciclo vicioso em que as pessoas não conhecem ou são fluentes em dados e acabam perdendo oportunidades tende a se agravar uma vez que a utilização e interpretação de dados estão associadas a parte substancial da informação e conhecimento disponíveis. A expressão Alfabetização em Dados, que é também tendência de 2020 de acordo com o Radar SGB, denota então uma necessidade e forma de inclusão. Para designers e pessoas visuais, olha só essa dica sobre alfabetização em dados: no texto recente publicado por Leandro Amorim no Radar SGB – que vale muito a leitura – ele descreve que o letramento em design é essencial para a compreensão da exibição de dados e a comunicação do seu conteúdo, entre muitos outros aspectos.
Hoje, como Estatística de formação e Cientista de Dados, atuo diariamente com a provocação de desenvolver uma cultura data-driven para que as tomadas de decisão sejam responsáveis e coerentes com objetivos e valores do meu time e trabalho. Isso só é possível rompendo as fronteiras da comunicação entre a ciência-fim e as tecnicalidades de dados. Posso dizer que eu sei, na prática, os ganhos de instruir – quando cabível – e entender e se fazer entendido nesse admirável mundo novo de dados. Além da alfabetização para leitura e entendimento de dados chamo a atenção para a urgência da compreensão dos diferentes tipos de análise disponíveis, assim como suas áreas de estudo e literatura. Esse post descreve conceitos importantes, exemplifica algumas técnicas e situações hipotéticas que motivam o seu uso.
Conceitos de dados bem definidos valem mais que mil palavras, mas… precisam de exemplos.
Em geral, queremos compreender alguma coisa (assim, bem genérico) da realidade. Se esse aspecto fosse fácil de entender, provavelmente não existiria a necessidade de um estudo com dados. Então, podemos dizer que trata-se de algo difícil de assimilar, e chamamos essa quantidade de variável resposta, denotada por Y. Dessa maneira, usamos outros aspectos da realidade que também podemos observar e que se relacionam com Y. Ou seja, vamos estudar algo complexo (Y) a partir de quantidades associadas a ele, as chamadas variáveis explicativas, covariáveis ou features, X. Dizemos, então, que vamos criar um modelo de Y em função de X. Um modelo é uma abstração – Estatística, Matemática, Computacional – que representa o fenômeno complexo de interesse.
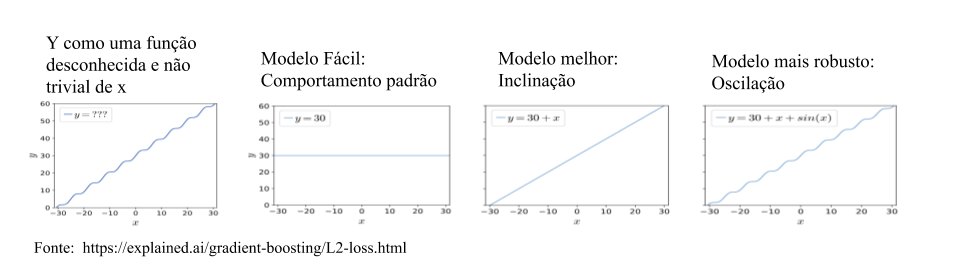
De um modo simplificado (beeem simplificado), dizemos que há 03 possíveis usos da relação estabelecida abstratamente por Y e X: para estabelecer correlação, para estabelecer causalidade e para permitir predição.
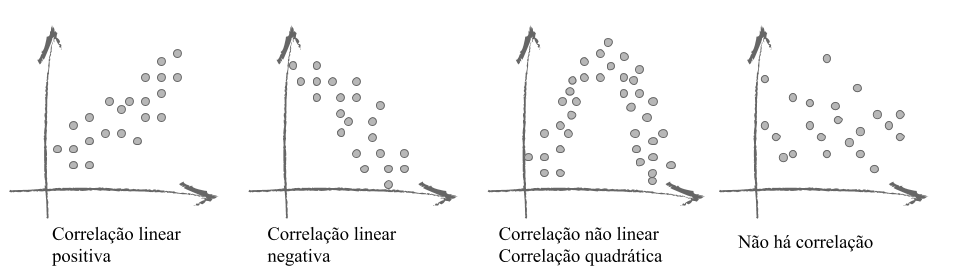
Correlação diz respeito ao fenômeno de observar duas variáveis se relacionando, como vemos na imagem abaixo em que observamos distintas formas de associação entre as variáveis. Na prática, trata-se de um único número representando a direção e a intensidade da relação entre variáveis.
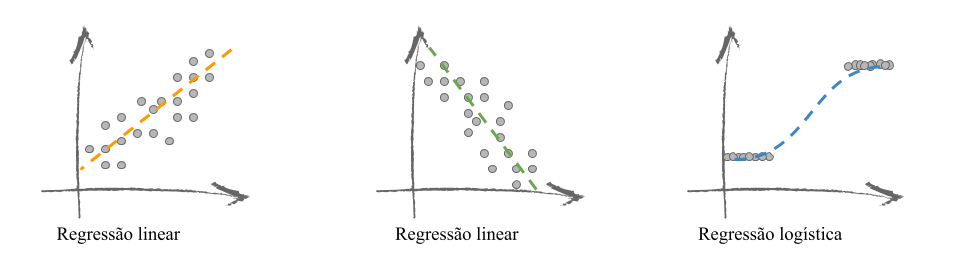
Um modelo comum que usualmente se confunde com o entendimento de correlação é o modelo de Regressão. Nesse caso, ajusta-se uma função matemática que representa como mudanças em X implicam mudanças na ocorrência de Y. A Regressão também quantifica direção e intensidade da relação entre X e Y mas o faz com o uso de uma uma equação, como vemos na figura a seguir.
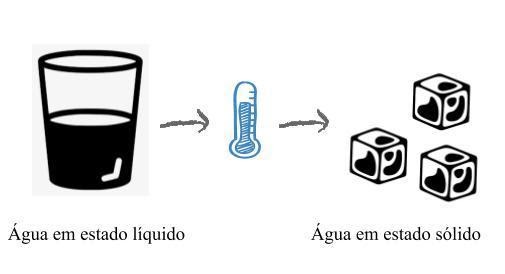
Estabelecer causalidade denota a possibilidade de afirmar que uma variável implica em outra. Nesse caso, o exemplo mais comum é o comportamento da água quando sujeita a um fato conhecido da Física: sua exposição a uma temperatura negativa. Note que a afirmação é tão forte que o exemplo mais comum descreve um comportamento determinístico (aquele que replicado sob as mesmas condições resulta no mesmo fato).
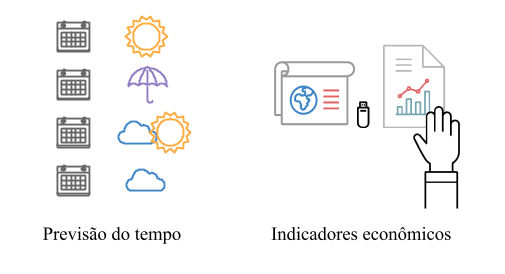
E predição corresponde ao ato de fazer previsões ou afirmar o que vai acontecer no futuro, como o fato comum de predizer a temperatura de uma região ou indicadores econômicos de uma empresa ou país.
Digo, por minha conta e risco, que:
estabelecer causalidade e viabilizar predição coerente estão para ganhar uma maratona.
Assim como:
estabelecer correlação está para efetivamente correr a maratona.
Podemos associar causalidade e predição a uma metodologia em dois passos. Desse modo, as suas qualidades finais são intrinsecamente dependentes da etapa de associação de variáveis e a quantificação dessa relação. Felizmente, dispomos hoje de inúmeras formas de modelagem de dados, as quais servem ao propósito de generalizar o uso da técnica a dados de natureza distintas dando mais aplicabilidade a elas.
Estatística, Inferência Causal e Aprendizado de Máquina
Ambas as áreas de Estatística, Inferência Causal e Aprendizado de Máquina lidam com dados e destinam-se a viabilizar tomadas de decisão. Em Estatística, os dados disponíveis são usados para aprender sobre dados não observados mas que seriam possíveis de observar, caso obtivéssemos uma amostra de tamanho maior. Já em Inferência Causal, os dados são utilizados para o aprendizado de quantidades impossíveis de serem observadas. Considere por exemplo uma situação em que o intuito é quantificar o valor de uma intervenção pública em um grupo de indivíduos vulneráveis. Em se tratando de indivíduos, só podemos observar uma dentre duas possíveis condições: ou o indivíduo recebe a intervenção ou ele não recebe. Dessa maneira, só dispomos da informação do que foi observado, por indivíduo. O aumento da amostra não viabiliza conhecer o efeito final de um indivíduo exposto às duas condições pois é literalmente impossível que ele passe por ambas as situações. Por fim, em contextos de predição, o interesse predominante é desenvolver capacidade de prever valores de Y dadas características X. Ou seja, antecipar a ocorrência da variável Y.
Exemplificando e diferenciando
Vamos exemplificar considerando uma situação hipotética de concessão de um benefício a estudantes, como uma bolsa de estudos. Logo, pode-se dizer que há duas populações distintas: o conjunto dos alunos beneficiários e o conjunto dos alunos que não usufruem do amparo.
Em um primeiro caso, suponha que o interesse seja comparar as notas médias das populações em estudo.
Vamos entender a situação: a imagem abaixo à esquerda representa essa comparação. Dizemos que existe uma distribuição das notas por população. Essa distribuição corresponde à frequência de cada nota, por grupo de alunos (demarcados pela cor). É natural imaginar que, independente de receberem o benefício ou não, cada grupo de alunos tem uma nota média. Essa nota média pode ser considerada como um comportamento padrão do grupo. É bastante razoável que as notas sejam mais frequentes/comuns ao redor da nota média e menos comuns afastando-se dela.
Vamos entender as expressões: O comportamento de notas mais concentradas perto da média – denotado tecnicamente por Normal ou Gaussiano – é descrito nos gráficos com as barras coladas, chamado de histograma. As barras mais altas denotam maior frequência, em ambos os grupos, e são aquelas no centro das representações. O comportamento central/padrão ou médio, por grupo, está representado pelas linhas pontilhadas.
É possível comparar comportamentos? Trata-se de um problema clássico em Estatística, em que se compara o comportamento médio por grupo por meio da intuição. Ou seja, vamos comparar a distribuição padrão das notas dos alunos com e sem bolsa. Uma comparação estatisticamente significante significa que: para concluir pela diferença de médias foram levados em conta as variabilidades ou dispersões de cada grupo. Desse modo, pode-se concluir que a diferença observada não é decorrente de uma flutuação aleatória, revelando um comportamento sistemático dos grupos.
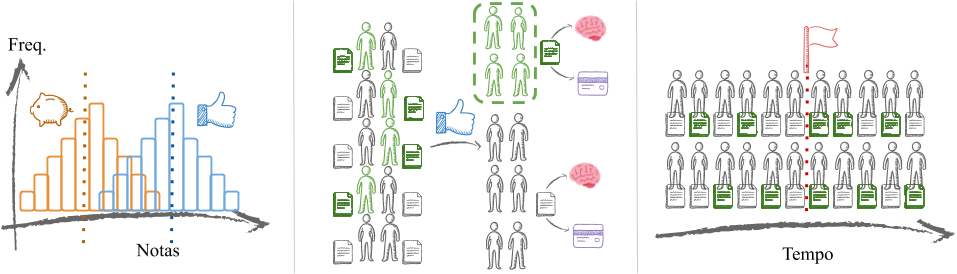
Outra possível análise corresponderia responder à seguinte questão: o benefício da bolsa melhora as notas dos alunos? A pergunta traduz uma relação de causa e efeito que poderia ser reformulada como: a ação da concessão de bolsa diretamente causa a melhora no desempenho dos alunos? Essa pergunta é representada na imagem superior central.
Imagine que a concessão da bolsa tem como critério a ser obedecido pelos elegíveis: obtenção de nota em certo exame superior a um ponto de corte C pré-determinado. Aqueles alunos com nota superior a C recebem o incentivo e os demais não. Afirmar que a bolsa é responsável pelo desempenho superior dos alunos é bastante ambicioso. Em se tratando de um grupo que recebe o benefício por ter desempenho superior em um exame podemos presumir que trata-se de alunos com grande potencial de aprendizado e/ou esforço. Logo, pode existir diferenças não observadas nos grupos – além da mera concessão da bolsa – um conceito conhecido como viés de seleção.
Um jeito alternativo de avaliar a concepção do benefício corresponderia a comparar os desempenhos dos alunos antes e depois da existência do programa. Esse seria um raciocínio intuitivo, não é mesmo? É um jeito de pensar quando a concessão do benefício não se baseia em um critério quantitativo específico. Ou seja, não selecionam-se elementos, o programa é concedido à população aplicável. A abordagem “temporal” está ilustrada na figura acima no frame mais à direita. O marcador do início do programa está representado pela bandeirinha. Nesse caso, o intuito também é estabelecer uma relação de causalidade. Afinal, queremos saber se a intervenção da concessão de bolsas de estudo altera os resultados dos desempenhos dos alunos.
Estabelecer a relação de causalidade é tarefa ambiciosa e existem metodologias conhecidas para tanto, sobretudo na literatura de Econometria e Avaliação de Impacto. Em geral, o estabelecimento de causalidade utiliza o conceito de um grupo similar ao dos participantes a menos da intervenção avaliada de modo a possibilitar comparações. Desse jeito, usualmente definem-se grupos: de intervenção (que recebe o efeito da política) e controle (mantido como o usual, sem a política proposta), conceitos apresentados na imagem abaixo, frame à esquerda.
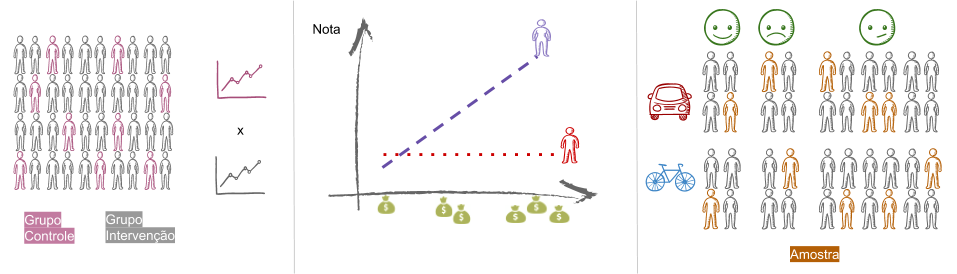
Podem existir combinações distintas de variáveis a serem estudadas/observadas, chamadas fatores, os quais usualmente relacionam-se com a variável resposta final mas também entre si, descrevendo um fenômeno conhecido como interação. Podemos pensar, por exemplo, que o efeito da concessão de bolsa pode se diferenciar por gênero ou classe de renda de sorte a levar ambos os efeitos em consideração na análise. Esses conceitos são ilustrados na imagem acima, na figura central.
Já estamos falando de conceitos de Experimentação, em que fala-se, dentre outras coisas, de Delineamento Fatorial e Análise de Variância. Também é imprescindível acessar a literatura de Amostragem, que denota o conjunto de técnicas para a seleção de uma parcela representativa da população. Uma representação de um delineamento amostral é apresentada na imagem superior à direita em que selecionam-se elementos da amostra respeitando as proporções das características populacionais (modo de locomoção e satisfação com o período de locomoção ao trabalho, por exemplo.)
Uma ferramenta comum na aferição de Causalidade é a já citada Análise de Regressão. Especialmente no que tange a Avaliação de Políticas Públicas, existe uma literatura crescente que recebeu esse ano estímulo e reconhecimento com a concessão do Nobel de Economia 2019 para os trabalhos de Kremer, Banerjee e Duflo. Tem tanta coisa incrível rolando nesse mundo que merece um post em separado, né?
Por fim, mas bem longe de ser menos importante, uma análise destinada a prever a concessão (ou não) do benefício em função de características dos aplicantes também é muito plausível. No contexto em que intui-se aferir antecipadamente o número de elegíveis a um dado programa, uma ferramenta de predição dessa quantidade é essencial para um planejamento coerente.
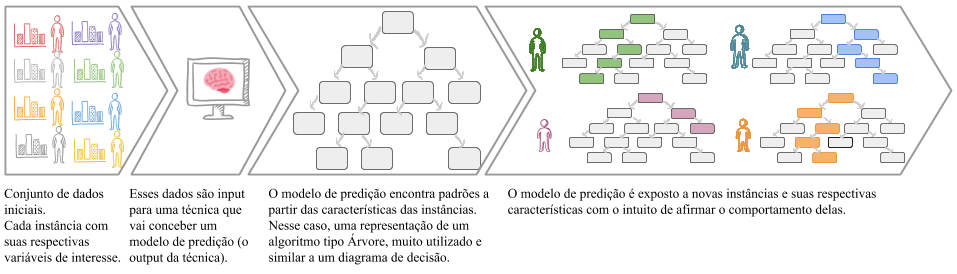
A imagem abaixo descreve um framework típico de predição. Começa-se com um conjunto de elementos/instâncias representadas por suas características/variáveis. Essa massa de informação é o input de um algoritmo de Aprendizado de Máquina. Essa é uma expressão que denota a concepção de um modelo preditivo, usualmente, sem a interferência de um componente humano. Ou seja, define-se um modelo para previsão que, a menos de alguns parâmetros, é orientado por dados, ou data-driven.
A etapa de Aprendizado resulta em um modelo, ilustrado pelo diagrama de decisão, uma representação comum para a classe de algoritmos de Árvore. Esse modelo será usado predizer o comportamento de novos elementos. No exemplo citado, o algoritmo seria induzido com dados de histórico dos alunos aplicantes do programa. Para cada novo ano, seria possível avaliar a quantos aplicantes seria dada a bolsa, predizendo o seu desempenho no exame de concessão do benefício, com base no modelo induzido.
Conclusões
O mundo de Análise de Dados não é recente. Há um enorme histórico de metodologias e conceitos. Métodos e literaturas se misturam e se confundem por áreas de aplicação.
A alfabetização em dados permite reconhecer o potencial de aplicação dos seus dados, ou seja, viabiliza dimensionar o impacto das tomadas de decisão advindas da análise de dados. Além disso, saber definir – mesmo que brevemente – o problema em função das informações disponíveis reduz o esforço do profissional que trata e analisa os dados.
E cabe repetir: alfabetização em dados possibilita o seu uso de modo coerente e ético.

{kind=link}
1 comentário
Amei seu blog 🙂 Parabéns!!!